Amazon S3 - The Basics
D
I love the web 🕸
I also write about personal finance in Spanish at https://perrodinero.blog
Search for a command to run...
I love the web 🕸
I also write about personal finance in Spanish at https://perrodinero.blog
No comments yet. Be the first to comment.
I've been wanting to learn Rails since ages ago, but, you know, life was getting in the way (or me, rather). A couple of weeks ago I decided to start a side-project related to another side-project. Sounds like an entry for a GitHub Graveyard, I know....
Sometimes we only need a font for a couple of words, like a logo or slogan. Why do we download the whole font file if we only need a few letters? In this post, I'll show you how you can reduce your font file size by more than 80%. This size reduction...

Queues are a natural phenomenon in everyday life. You queue to buy food, to pay in the supermarket, or to get on a plane. But queues are also used in software to handle heavy processes. A queue can help devs like me and you store a request for later ...

Software development is hard. Time zones are hard. Dealing with time zones in software development? Yeah, harder. Here are 4 places where time zones might differ; and 4 personal bug stories for each case. I'll be referring to the same app for each s...

I started the #100DaysOfCode challenge on March 21st and finished it today, August 7th. FINALLY! 🥳 And yeah, that's way more than 100 days 🙃 For those who don't know, the #100DaysOfCode challenge consists of coding at least one hour every day for t...
Amazon Simple Storage Service, called S3, is an object storage solution to reliably store and retrieve any amount of data.
It can store your files, build packages, reports, images, and any type of data you can think about for later retrieval with a guaranteed 99.999999999% durability. Also, it can restrict access to specific data with very flexible rules.
S3 is extremely reliable and flexible. You want to use it if you at some point need to store and retrieve:
Also, it has tons of integrations with other services within AWS.
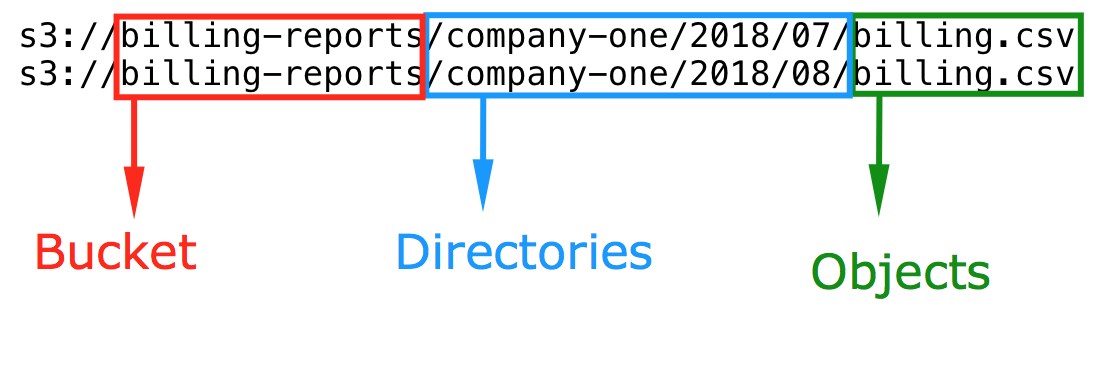
A Bucket is like a top level directory in Linux in the sense that it is a node in level one. A bucket is then the "directory" that stores a group of objects or more directories (with no quotes since these are proper directories now). More clarification below.
Objects are the files itself. A bucket can contain many objects.
Bucket and objects example:
S3 bucket policies are the set of rules that explicitly define who has or not access to your bucket and to objects within that bucket.
Access Control Lists is yet another way to define access to your buckets and objects. However, this is a legacy access control mechanism, so it's best to focus on bucket policies. The cases in which ACLs are needed are, for example, when a bucket policy grows too large- they are limited to 20 kb in size. Or when you want to restrict access to specific objects within a bucket.
Lifecycle rules are actions that S3 can apply to a group of objects depending on how much time they have been stored. For instance, you can delete objects that have been on your buckets for more than 90 days.
Apart from these concepts, one of the most important things to know about S3 is its consistency model.
The consistency model of S3 is called Read-after-Write consistency. For example, if you issue a PUT request to create an object on a bucket, the next GET request will ALWAYS have the desired object.
However, if you try to issue a GET first (object being non-existent), then a PUT and then another GET, you MIGHT not found the desired object. Issuing the request in this order, the consistency model is now called eventual consistency.
In other words:
Read-after-Write consistency:
Eventual consistency:
You also get eventual consistency when you delete an existing object. That is, you MIGHT see an object listed on your bucket even though you already deleted it a couple of seconds ago.
This is because changes made to your S3 buckets need some time to propagate and replicate through AWS servers.
This covers the very basics of S3 which are enough to get started with the service. S3 is one of the most used services of AWS due to its reliability, durability and integration with many other services inside and outside AWS.
Thanks for reading me! ❤️